Rancher 1.2之于之前的版本在很多地方都有颠覆性的更新,今天我着重来谈网络方面。在1.2中Rancher实现了对CNI的支持,通过network-plugin来实现对CNI的调用;另外,network-plugin还实现了如为暴露端口的容器配置DNAT,MASQUERADE等操作。
Rancher v1.2网络现状
但是,v1.2版本也并非彻底的拥抱CNI,原因如下:
- Network-plugin默认为必选项,其内部自动检测容器是否expose端口到host,并为容器端口配置DNAT规则;另外,所有容器默认使用docker0经过三层转发(通过Iptables规则控制)来访问外网,即全部配置MASQERADE;这一点限制了网络模型(二层广播域只能在host内部),将影响到希望使用另一张网卡来实现扁平网络的用户;
- Network-plugin的启动依赖于Metadata,而Metadata和DNS server均使用docker0的bridge网络(IP为169.254.169.250)。即,用户私有化的CNI网络必须要能够访问到docker0网络,否则Rancher提供的服务发现与注册以及其它为业务层提供的服务将不可用。
- 不支持多个网络,官方宣称只能选择一个CNI网络,在UI中对所添加的各类型的CNI网络均显示为托管网络。其中系统基础服务比如scheduler、health check以及load balance默认均只能在托管网络内工作。如若手工添加了其它CNI网络,将导致第二个CNI网络内,scheduler、health check以及load balance异常。
客户需求
- 在很多场景中用户对于容器网络的使用,还是希望业务与管理隔离,即通过一张独立的网卡来运行业务流量。
- 在混合组网的场景中,用户一部分业务运行在裸机中,另一部分业务运行在Rancher容器内,将这两张网络统一为一张扁平化网络的呼声也较大。
解决方案
基于Rancher 1.2中CNI的诸多限制,有没有办法去实现扁平网络呢?答案是肯定的!
网络整体拓扑
先看一张网络部署图,下图可分为两个区域,Rancher区域与裸机区域。
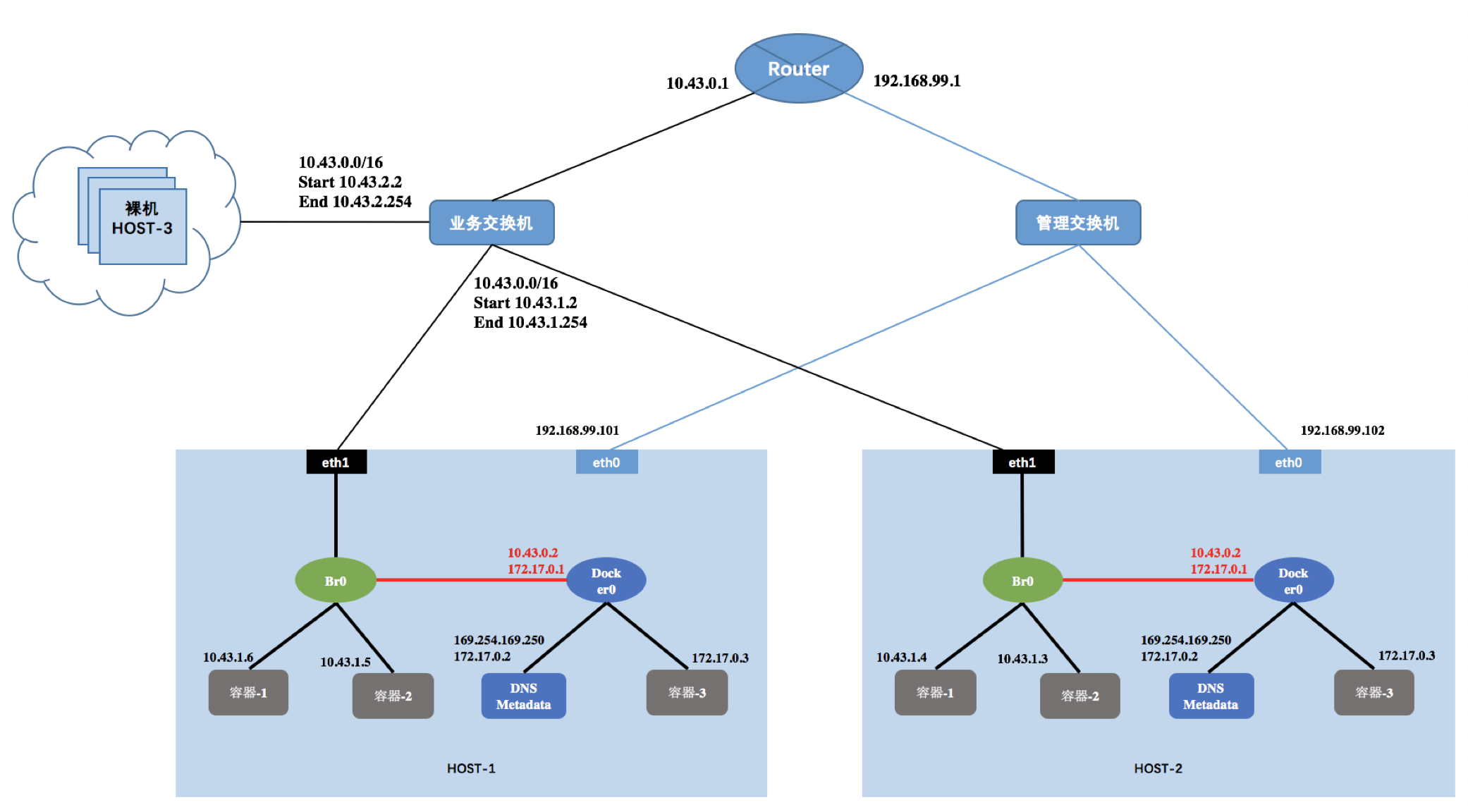
Rancher区域
HOST-1和HOST-2分别为Rancher的agent节点(每个节点有两张网卡),按业务划分,该区域内部可以通过容器部署一些变动大、常启停或常扩缩容的业务。
裸机区域
Host-3以及其它主机为物理服务器(即裸机),按照业务划分,host-3上可运行一些相对业务对硬件资源要求较高,且不常变动的业务组件。
这两个区域通过业务交换机二层互联,如果网络规模小,这样的拓扑结果是没有问题的。如若网络规模大,需要考虑广播域的问题,为了避免广播风暴,一些客户会使用一些支持SDN的设备来取代业务交换机,从而对二层广播做限制。
扁平网络内部(包括两个区域的所有主机)统一使用外部的路由器做网关,比如图中,Rancher内部的容器的子网范围为10.43.0.0/24, IP地址池范围为10.43.1.2-10.43.1.254。同理,裸机域内,子网范围为10.43.0.0/24, IP地址池范围为10.43.2.2-10.43.2.254。
之所以要将管理网络和业务网路经过同一个路由器(或者防火墙)是因为scheduler需要访问cattle,即管理网;另一方面,scheduler又需要由CNI网络中的health check 做健康检查和故障恢复。若考虑安全问题,可以在防火墙上配置规则,对业务网对管理网的访问做限制。
Rancher内部CNI网络
内部CNI网络主要需要解决两个问题:
- 如何访问Metadata和DNS server的地址169.254.169.250;
- 采用独立的网卡来转发业务流量后,二层广播域跨主机了,若每台主机上还通过同一个IP 169.254.169.250访问DNS和Metadata服务,如何解决地址冲突的问题;
下图是宿主机内部CNI网络的拓扑图以及流量转发规则:
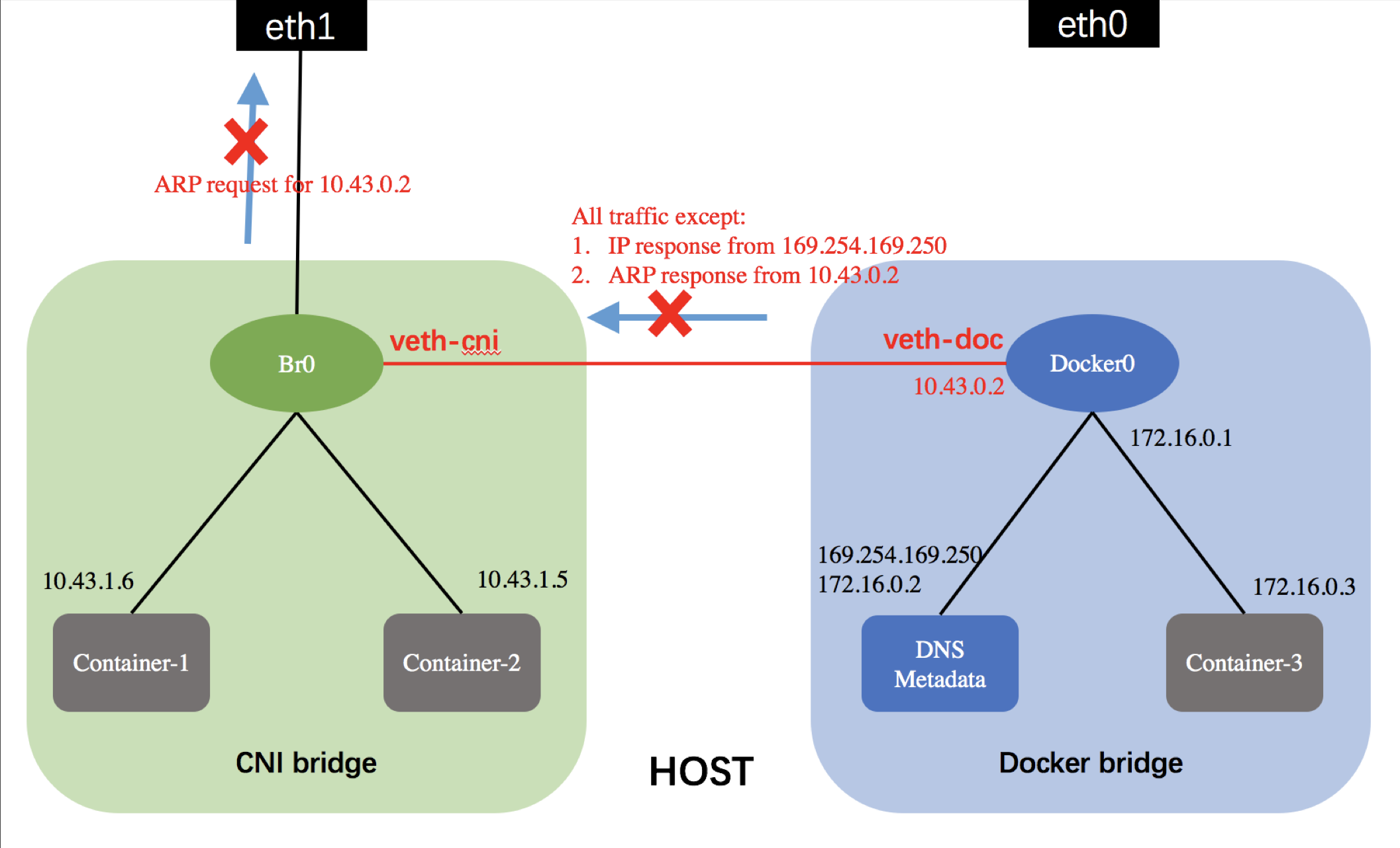
由于扁平网络需要使用自定义的bridge,与docker0无关。同一个network内部的所有容器属同一个二层网络,且都不可见169.254.169.250地址。为了让容器可以访问该地址,我们采用将br0(CNI bridge)与docker0连通,然后再该链路上的流量做限制来实现。具体如下:
- container-1内部有到达169.254.169.250的一条主机路由,即要访问169.254.169.250需要先访问10.43.0.2;
- 通过veth-cni与veth-doc的链接,CNI bridge下的container-1可以将ARP请求发送到docker0的10.43.0.2地址上。由于10.1.0.2的ARP response报文是被veth-cni放行的,于是container-1能够收到来自10.43.0.2的ARP response报文。
- 然后container-1开始发送到169.254.169.250的IP请求,报文首先被送到docker0的veth-doc上,docker0查询路由表,将报文转到DNS/metadata对应的容器。然后IP报文原路返回,被docker0路由到veth1上往br0发送,由于来自169.254.169.250的IP报文都是被放行的,因此container-1最终能够收到IP。
- 由于属于该network的所有的宿主机的docker0上都需要绑定IP地址10.43.0.2;因此,该IP地址必须被预留,即,在catalog中填写CNI的netconf配置时,不能将其放入IP地址池。
- 同时,为了保障该地址对应的ARP请求报文不被发送出主机,从而收到其他主机上对应接口的ARP响应报文,需要对所有请求10.1.0.2地址的ARP REQUEST报文做限制,不允许其通过br0发送到宿主机网卡。
具体转发规则对应的ebtables规则如下所示:
Drop All traffic from veth-cni except:
- IP response from 169.254.169.250
- ARP response from 10.43.0.2
1 | ebtables -t broute -A BROUTING -i veth-cni -j DROP |