研究了rocket-mq之后,一直想知道为什么kafka会这么火, 终于有时间学习了一下这块的内容, 简单总结以备以后查阅。
部署架构
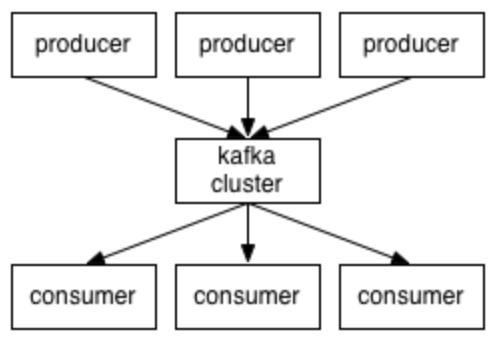
其实这个架构和rocket-mq比较像,差异是rocket-mq使用了nameserver,而kafka使用zookeeper来做配置协调中心。
组成原理
主要涉及kafka从broker启动、生产者发送消息、broker分发消息到消费者消费消息的流程。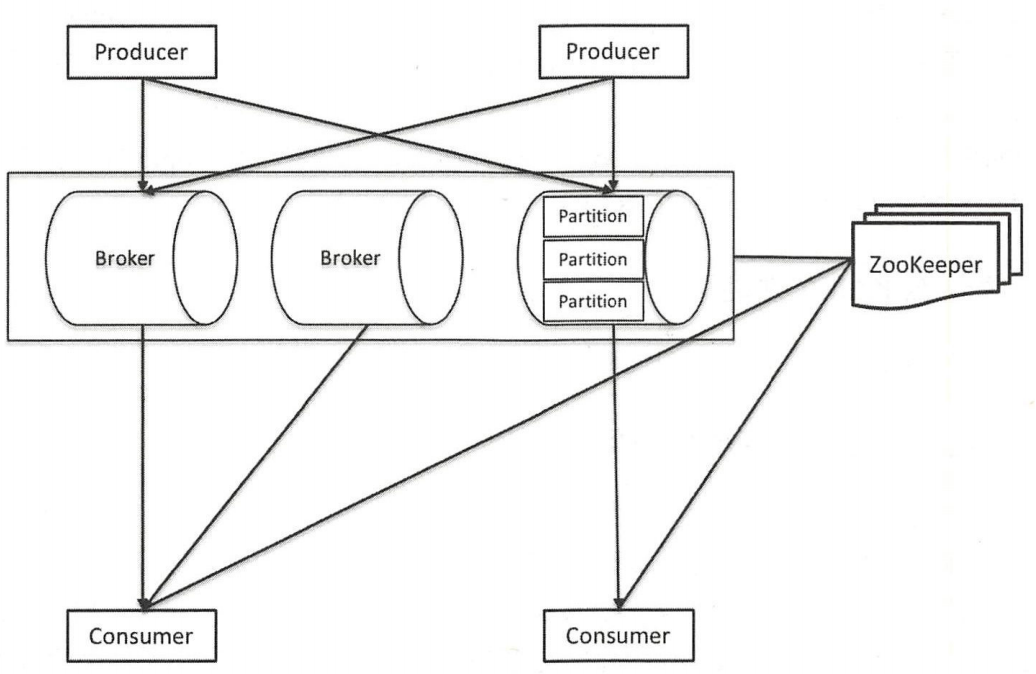
服务注册
- 所有的broker启动后都注册到zookeeper,写到
/brokers/ids目录下; - Broker组件订阅这个路径,当有borker加入、删除就能够立即知道其broker的信息了;
- 健康检查机制,Broker长时间丢失连接会被自动回收;
- 基于此,producer在配置的时候,并不需要填写所有broker的地址,只需要填写几个broker的地址就可以通过他们去发现自己需要写topic的broker了。
Controller的作用
- Broker起来后选举出一个controller,controller是使用锁的方式来实现的。即在zookeeper的
/controller目录,谁先写入数据,谁就是controller; - 新的controller会获得一个递增的epoch,如果其他broker收到老controller发出来的消息,消息体重会带着旧的epoch,就直接忽略消息;
- 其他broker会一直watch
/controller的变化;并等待当前controller挂了之后抢占controller的地位。 - controller的职责是管控broker与topic中partition主备映射关系;
- 当broker挂掉、新加broker时,controller通过watch可以感知到变化;它会通过分析挂掉的broker中的partition的副本来重新选举出partition的leader,并将变化下发到相关的broker;
生产者
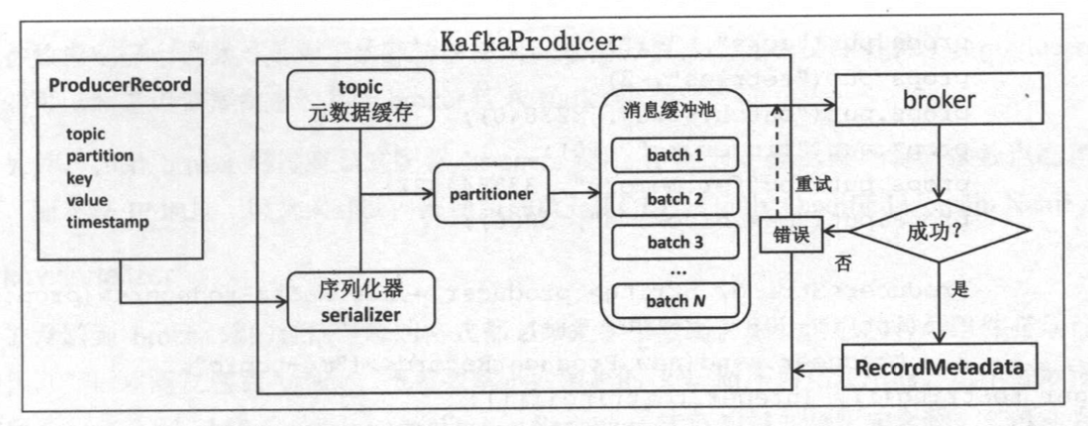
- Producer先序列化数据,按照topic分类(下面还有key/value),然后按照负载均衡算法push消息到topic的不同partition;
- Producer发送消息的模式有三种: oneway(结果未知), sync(阻塞), async(有回调函数);
- Producer可以设置Acks方式,可以设置为: 1. 发送后立即返回(0); 2. 等待主partition保存后返回(1); 3.等待副本patirion复制完成后返回(-1);
Topic与Partition
- Topic可以有多个partition,可以基于各种算法来将消息分类到不同partition,拥有同样key的消息会放到同一个partition;
- partition是物理实现,可以指定partition的副本数;
- Topic下的partition数量可以递增,但是不能递减;
Kafka的设计也是源自生活,好比是为公路运输,不同的起始点和目的地需要修不同高速公路(
主题),高速公路上可以提供多条车道(分区),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了。
分区再分配
- 新增的broker是不会自动地分担己有topic的负载的,它只会对增加broker后新创建的topic生效;
- 如果要让新增 broker为己有的 topic服务,用户必须手动地调整己有topic的分区分布,将一部分分区搬移到新增broker上。这就是分区重分配(partition reassignment);
- 可以基于自带的脚本
kafka-reassign-partitions.sh来实现,该脚本分为generate和execute阶段,generate阶段可以看到系统推荐分配的方案; - 使用脚本
kafka-reassign-partitions.sh,同样可以为topic增加副本数。
Parition主备复制
- kafka的高可用是通过topic的每一个partition多个副本来实现的;
- partition的副本负责从leader拷贝数据,数据中包含了offset等信息;
- kafka的leader负责处理外部的读写操作,follower不对外服务,只有备份的作用;
- partition的副本会发送回复信息给leader,leader基于此来判断副本是否保持同步;
- 只有同步的分区副本才能在leader挂后被选为新的leader;
- 消费者只能看到已经被复制到ISR(in-sync replica)的消息,分区副本从leader复制消息之前,理论上leader是不允许该消息被consumer消费的,因为这样的消息不安全。
- 因为各种各样的原因,一小部分replica开始落后于leader replica的进度。当滞后到一定程度(
replica.lag.time.max.ms)时,Kafka会将这些replica “踢”出 ISR。当这些replica重新“追上”了leader的进度时,那么Kafka会将它们加回到ISR中。 - kafka几个关键数据:
HW(high water)代表follower已经同步的offset;LEO(log end offset)代表leader/follower的数据结尾offset。LAG代表consumer的偏移,(LAG = HW - Consumer offset)。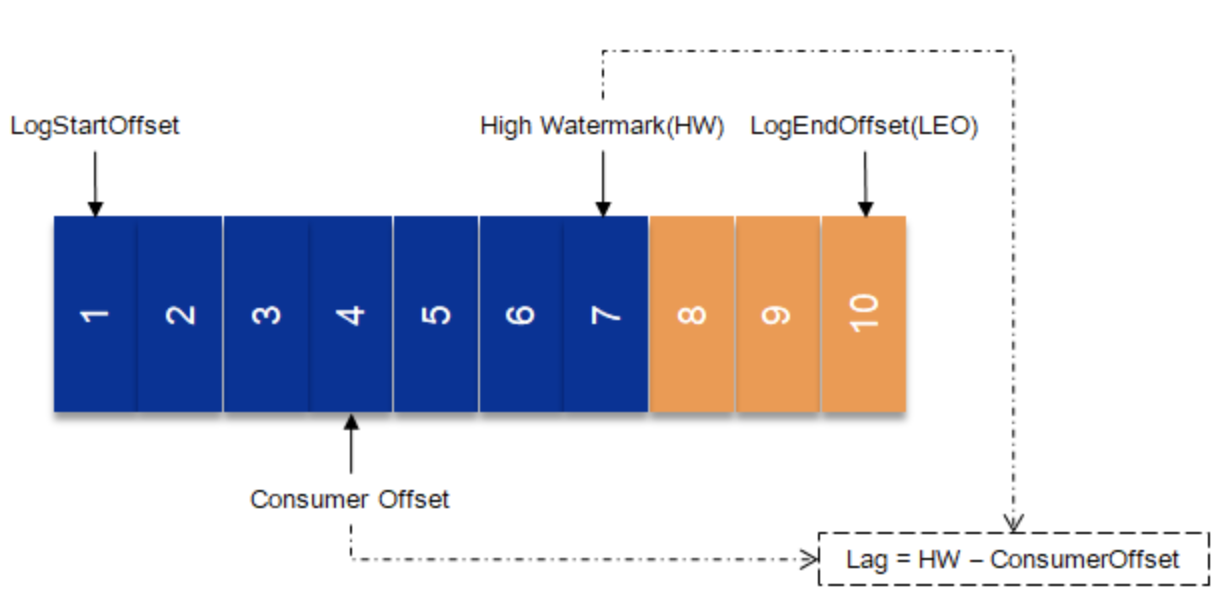
消费者组再均衡
- 这里的再均衡是针对consumer group中的consumer来讲!
- Topic如果增加partition,或者consumer group中的consumer有变动,均需要重新分配分区(再均衡);
- Consumer的变动是通过定期向broker协调者发送心跳报文来实现的,心跳报文中包含了群属关系以及分区所有权关系;
- 在再均衡期间,消费者无法读取消息;
- Consumer读取消息,并将offset发送到一个__consumer_offset的特殊
topic中,该消息包含了每个分区的偏移量; - 一旦再均衡后,新的consumer可以继续按照之前的offset工作;
__consumer_offset
- 可以把它想象成一个KV格式的消息,key就是一个三元组:
group.id+topic+分区号,而value就是offset的值。- 每次consumer读取了消息就往该topic发送消息,kafka负责执行压缩算法,只保留最新的offset数据。
- 该topic默认有50个partition
Rebalance协议
- JoinGroup请求
consumer请求加入组 (当收集全JoinGroup 请求后, coordinator从中选择一个consumer担任group的 leader,并把所有成员信息以及它们的订阅信息发送给leader)。 - SyncGroup请求
group leader把分配方案同步更新到组内所有成员中(一旦分配完成,leader会把这个分配方案封装进 SyncGroup请求并发送给coordinator。组内所有成员都会发送SyncGroup请求,不过只有leader发送的SyncGroup请求中包含了分配方案。coordinator接收到分配方案后把属于每个consumer的方案consumer group分配方案是在consumer端执行的单独抽取出来作为syncGroup请求的response返还给各自的 consumer)。 - Heartbeat请求
consumer定期向coordinator汇报心跳表明自己依然存活。 - LeaveGroup请求
consumer主动通知coordinator该consumer即将离组。 - DescribeGroup请求
查看组的所有信息,包括成员信息、协议信息、分配方案以及订阅信息等 。该请求类型主要供管理员使用 。 coordinator不使用该请求执行 rebalance。
消息存储
- Broker的消息保存策略为:
- 保存指定时间;
- 保存达到某一Size;
Log文件
创建topic时,Kafka为该topic的每个分区在文件系统中创建了一个对应的子目录,名字是: <topic>-<分区号>, 如operation-product-sync-4。
1 | [root@centos operation-product-sync-4]# ll -h |
.log文件是日志段文件,保存着真实的Kafka记录,Kafka使用该文件第一条记录对应的offset来命名此文件(默认最大1G);.index和.timeindex文件都是与日志段对应的位移索引文件和时间戳索引文件;每写入(log.index.interval.bytes,默认4K)数据才更新一次索引文件。位移索引保存的是与索引文件起始位移的差值。索引文件文件名中的位移就是该索引文件的起始位移;时间戳索引项保存的是时间戳与位移的映射关系,给定时间戳之后根据此索引文件只能找到不大于该时间戳的最大位移,稍后还需要拿着返回的位移再去位移索引文件中定位真实的物理文件位置。log compaction只会根据某种策略有选择性地移除log中的消息,而不会变更消息的offset值。kafka通过cleaner组件来压实log;该配置是topic级别的,必须指定key。
消费者
- Kafka支持Consumer group,它可以保障每一个group中只有一个consumer消费某条消息;
- 如果要广播消息,需要创建多个consumer group;
- Consumer的数量不要超过分区数量,否者某些consumer会闲置。
consumer group
- 一个consumer group可能有若干个consumer实例(一个group只有一个实例也是允许的):
- 对于同一个group而言,topic的每条消息只能被发送到group下的一个consumer实例上:
- topic消息可以被发送到多个group中。
调优
吞吐量
broker 端
- 适当增加 num.replica.fetchers,但不超过CPU核数。
- 调优 GC 避免经常性的Full GC。
producer 端
- 适当增加 batch.size,比如 100~512 KB
- 适当增加 linger.ms,比如 10~100 毫秒
- 设置 compression均pe=lz4
- acks=0 或 1
- retries = 0
- 若多线程共享 producer或分区数很多,增加 buffer.memory
consumer 端
- 采用多 consumer实例。
- 增加 fetch.min.bytes,比如 100000。
时延
broker 端
- 适度增加 num.replica.fetchers。
- 避免创建过多topic分区。
producer 端
- 设置 linger.ms=0
- 设置 compression.type=none
- 设置 acks=1 或 0
consumer 端
- 设置 fetch.min.bytes=1。
持久性
broker 端
- 设置 auto.create.topics.enable=false
- 设置 replication.factor= 3, min.insync.replicas = replication.factor - 1
- 设置 default.replication.factor=3
- 设置 broker.rack属性分散分区数据到不同机架
- 设置 log.flush.interval.message 和 log.flush.interval.ms为一个较小的值
producer 端
- 设置 acks=all
- 设置retries为一个较大的值,比如 10~300
- 设置 max.in.flight.requests.per.connection=1
- 设置 enable.idempotence=true 启用幂等性
consumer 端
- 设置 auto.commit.enable=false
- 消息消费成功后调用 commitSync 提交位移;
可用性
broker 端
- 避免创建过多分区
- 设置 unclean.leader.election.enable=true
- 设置 min.insync.replicas=1
- 设置 num.recovery.threads.per.data.dir=broker端参数log.dirs中设置的目录数
producer 端
- 设置 acks=1,若一定要设置为all,则遵循上面broker端的min.insyn.replicas配置
consumer 端
- 设置 session.timeout.ms为较低的值,比如 10000
- 设置 max.poll.interval.ms为比消息平均处理时间稍大的值
实践
规划
CPU: 使用多核( > 8core),但是对单核的主频要求不高;
内存: 主要用于page/cache,jvm使用的heap内存并不多(< 6G);
磁盘: 顺序读,HDD盘基本够用,没必要上SSD;
典型配置:
- CPU 24核。
- 内存 32GB。
- 磁盘 1TB 7200转 SAS盘两块。
- 带宽 1Gb/s。
- ulimit -n 1000000 (永久生效:
vim /etc/security/limits.conf)。 - Socket Buffer至少 64KB 一一 适用于跨机房网络传输。
kafka
在linux服务器上,下载并启动kafka服务。
1 | # 下载 |
验证消息的发送和消费。
1 | # 创建topic |
kafka-manager
虽然我们能够通过脚本的方式来操作kafka消费消息,但是没有一个理想的portal还是感觉这货不过直观,接下来介绍的就是一个差不多算是最好的kafka的dashboard,kafka-manager,由yahoo开发。
我们通过docker的方式来启动,镜像的具体信息参考这里
1 | docker run -d \ |
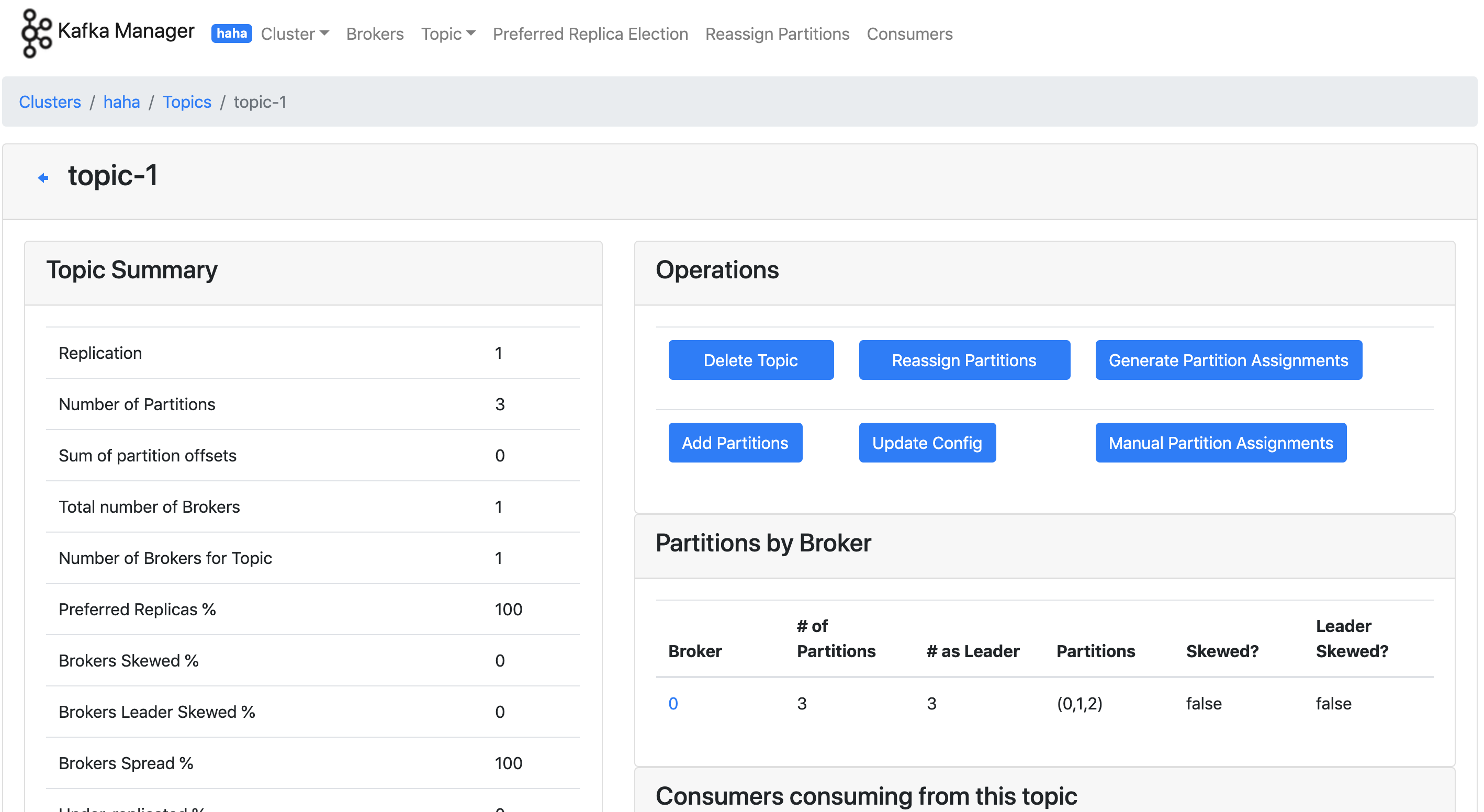
在浏览器中访问 http://{ip}:9000,可以看到界面。通过添加cluster,其实就是指定一下kafka对应zookeeper的地址;好了之后可以查看kafka集群的broker,topic,以及partition,consumer等信息。其界面如下图所示:
zookeeper UI
前面已经说到kafka没有UI感觉很懵逼,那zookeeper其实也是如此。我们知道zookeeper一方面是做分布式协调,另一方面也是作为DB来存储了kafka和kafka-manager的配置信息。这里我们也介绍一个工具来查看zookeeper中都保存了些什么东东,有助于我们了解kafka的原理。
这里要介绍的项目为zkui, 有兴趣可以去github了解一下。
1 | docker run -d --name zkui -p 9090:9090 -e ZK_SERVER=<zookeeper-ip>:2181 rootww/zkui |
启动之后,在浏览器访问http://{ip}:9090 就可以看到如下的界面(页面上有登录的账号信息,默认是admin/manager)。里面可以看到关于kafka和kafka-manager的配置信息。
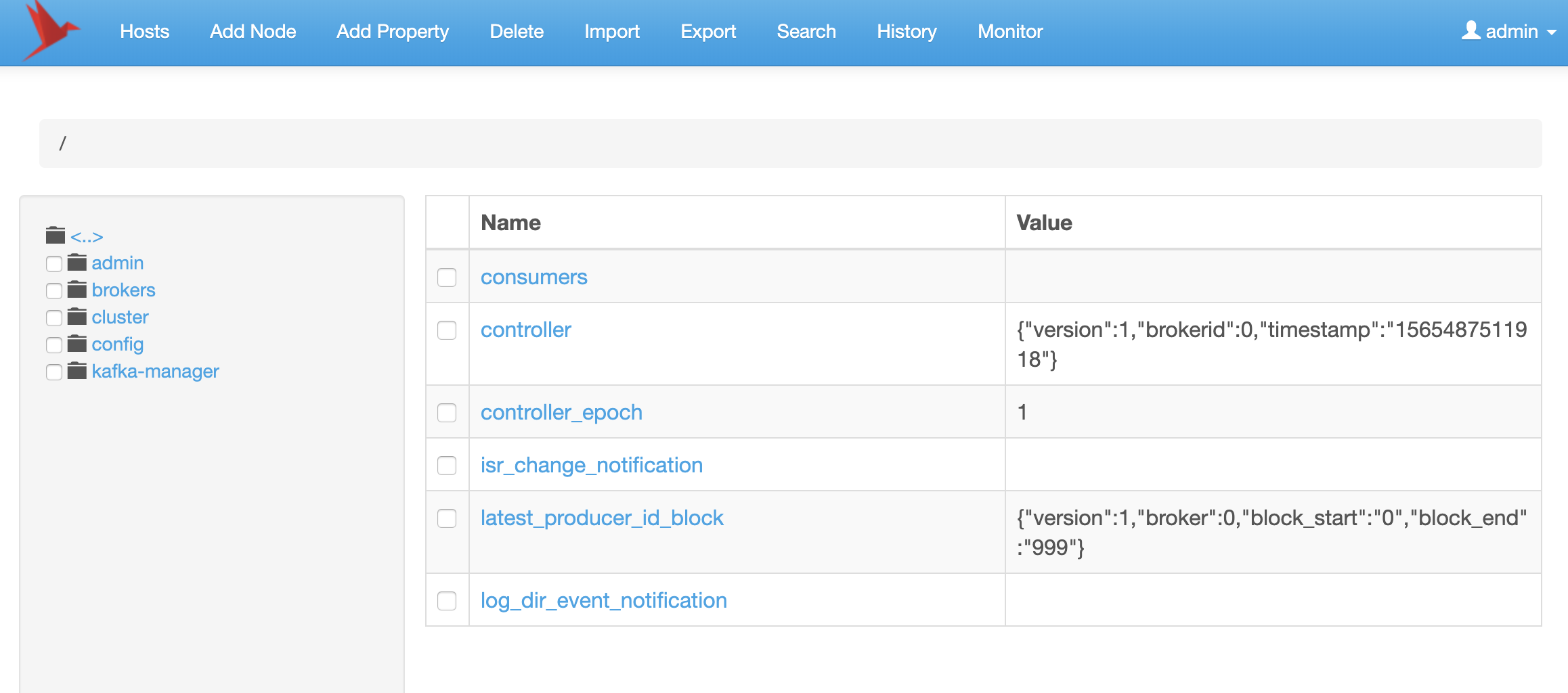
点击页面上的export菜单,还可以直接导出所有的zookeeper配置,这样便于我们直接查看各个key的value。
1 | #App Config Dashboard (ACD) dump created on :Sun Aug 11 11:21:04 CST 2019 |