Sqoop用来在关系型数据库与HDFS(Hive、HBase)之间导入和导出数据,其既可以作为ETL抽数据到DW的工具,又可以作为对DM处理好的数据导出到业务数据库的工具,其地位如下图所示: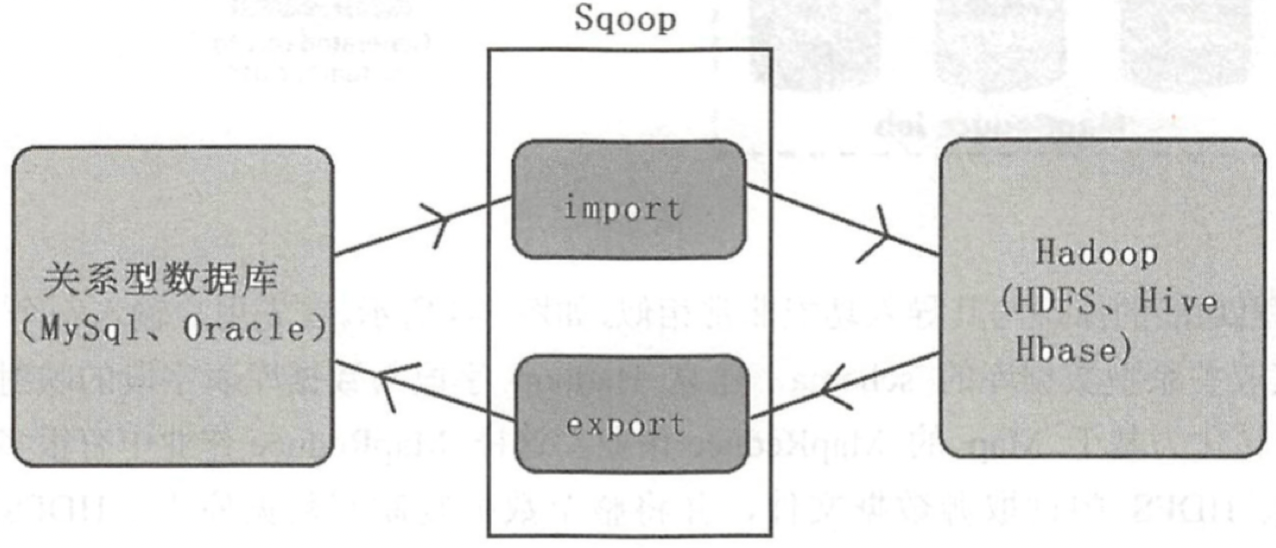
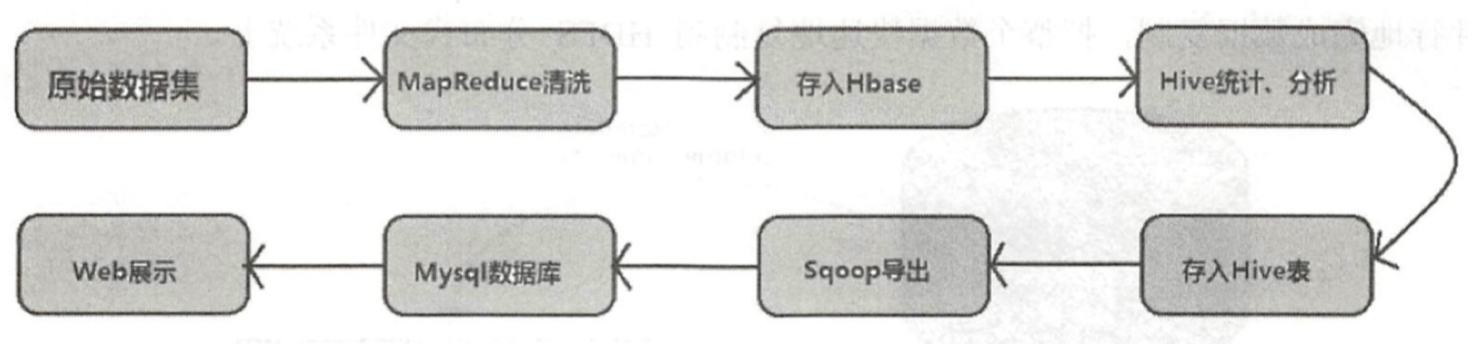
Sqoop主要通过JDBC和关系数据库进行交互。理论上支持JDBC的Database都可以使用Sqoop和HDFS进行数据交互。
原理
Sqoop有两个版本,他们之间的差异见下表:

我们这里重点将下Sqoop2的架构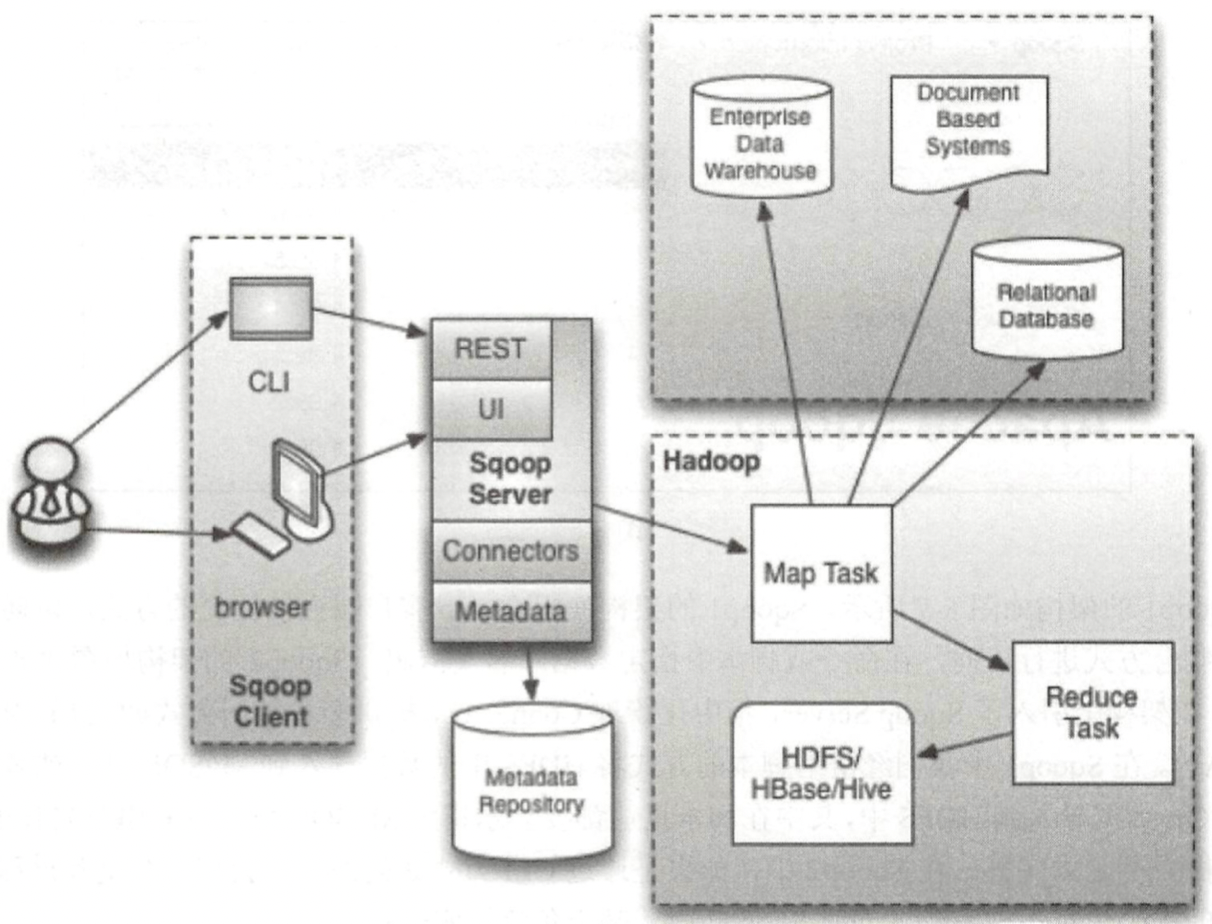
导入到HDFS
- 在导入前,Sqoop使用JDBC来检查将要导入的数据表;
- Sqoop检索出表中所有的列以及列的SQL数据类型;
- 把这些SQL类型的映射到java数据类型,例如(VARCHAR、INTEGER)->(String,Integer);
- 在MapReduce应用中将使用这些对应的java类型来保存字段的值;
- Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
导出到JDBC
- 在导出前,sqoop会根据数据库连接字符串来选择一个导出方法(对于大部分系统来说,sqoop会选择JDBC);
- Sqoop会根据目标表的定义生成一个java类;
- 这个生成的类能够从文本中解析出记录,并能够向表中插入类型合适的值(除了能够读取ResultSet中的列);
- 然后启动一个MapReduce作业,从HDFS中读取源数据文件;
- 使用生成的类解析出记录,并且执行选定的导出方法。
实践时间
将 MySQL数据库的表dept导入HDFS1
sqoop import --connect jdbc:mysql://10.10.75.100:3306/sqoopdemo -- username root --password root123 - table dept -m 1 -target-dir /user/dept
将数据从HDFS导出到MySQL数据库的表dept1
2
3
4
5
6
7
8
9
10sqoop export --connect jdbc :mysql://10.10.75.100:3306/sqoopdemo --username root --password root123 --table dept -m 1 --export-dir /user/dept
# Mysql->hive
sqoop import --connect jdbc:mysql://10.10.75.100:3306/sqoopdemo --username root --password root123 --table dept -m 1 --hive-import
# Hive->mysql
sqoop export --connect jdbc:mysql://10.10.75.100:3306/sqoopdemo --username root --password root123 -table dept -m 1 --export-dir /user/hive/warehouse/dept --input-fields-terminated-by '\0001'
# Mysql->hbase
sqoop import --connect jdbc:mysql://10.10.75.100:3306/sqoopdemo --username root --password rootl23 --table dept 一-hbase-create-table --hbase- table hbase dept --column-family colfamily --hbase-row-key id
更多操作方面的内容可以参考这篇Sqoop架构以及应用介绍。