kubeedge默认在云端部署edgeController和deviceController,然后通过websocket/quic隧道连接云端和边缘端,通过云端一个中心来统一调度应用到特定edge node上运行。但是,就像Rancher K3S的应用场景,有些时候边缘端也希望运行一套完整的k8s集群。K3S的方案只是提供了一套精简的k8s集群,而kubeedge的edgesite模式,除了运行k8s集群之外,还提供了对IOT设备的适配和支持。
架构
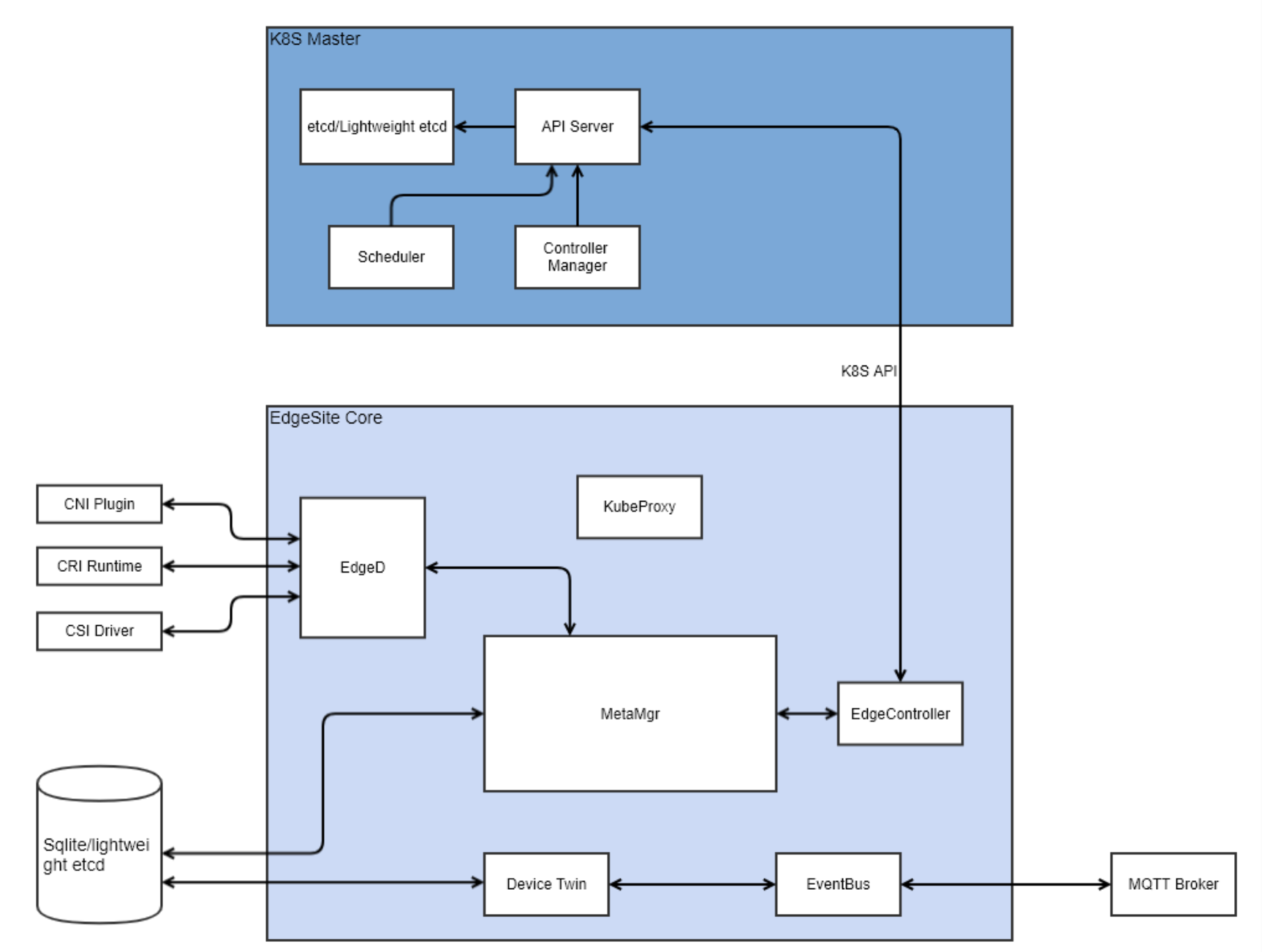
如上图所示,edgesite与传统的部署模式的差异在于edgeController与edged等之前边缘端的组件部署在一起;另外,k8s master虽然与下边的组件组没有画在一起,但是它们也被部署在边缘端。所以,没有了cloudHub和edgeHub之间基于隧道的通信。
这里可以看到,k8s master,也就是上面部分几乎是原生的k8s,不需要做任何改动;而下面部署就是kubeedge除cloudHub和edgeHub之外的所有组件。那代码能够直接复用?这在最后原理部分再来分析。
实验
这种架构,特别适合于已部署了一个k8s server端,在本地开发调试kubeedge组件的情况。在代码中加一些调试信息,本地快速编译,然后执行查看,方便快速理解代码逻辑。这里,我就要演示一把如何在本地运行kubeedge来对接到远端的k8s集群。
云端
我依然是使用在aliyun-vm上部署好的k3s集群,唯一需要注意的是,我在启动命令行中指定了参数,让api-server暴露了insecure-port 8080(这样本地就不需要指定各种证书信息了,当然为了安全,你也可以严格使用证书),具体如下:
1 | ~ $ cat /etc/systemd/system/k3s.service |
等待k3s启动之后,通过下面的node.yaml文件在k3s上kubectl apply -f node.yaml添加节点,注意节点的名称,后续edge端的配置文件需要设置为该名字。
1 | apiVersion: v1 |
边缘端
也就是我的本地笔记本,在kubeedge源码包中,有edgesite目录。需要进入到cmd目录中编译代码(这需要golang环境,这块不再介绍)、准备配置文件,并执行。
1 | ~ $ ls |
这里只需要修改edgeSite.yaml, 具体配置修改如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41mqtt:
server: tcp://127.0.0.1:1883 # external mqtt broker url.
internal-server: tcp://127.0.0.1:1884 # internal mqtt broker url.
mode: 0 # 0: internal mqtt broker enable only. 1: internal and external mqtt broker enable. 2: external mqtt broker enable only.
qos: 0 # 0: QOSAtMostOnce, 1: QOSAtLeastOnce, 2: QOSExactlyOnce.
retain: false # if the flag set true, server will store the message and can be delivered to future subscribers.
session-queue-size: 100 # A size of how many sessions will be handled. default to 100.
controller:
kube:
master: http://${k3s-api-server}:8080 # 这里是k3s的insecure-port的访问URL
namespace: "default"
content_type: "application/vnd.kubernetes.protobuf"
qps: 5
burst: 10
node_update_frequency: 10
node-id: edge-site
node-name: edge-site # 该名称为预先在k8s上创建的node名称
context:
send-module: metaManager
receive-module: controller
response-module: metaManager
edged:
register-node-namespace: default
hostname-override: edge-site
interface-name: eth0
node-status-update-frequency: 10 # second
device-plugin-enabled: false
gpu-plugin-enabled: false
image-gc-high-threshold: 80 # percent
image-gc-low-threshold: 40 # percent
maximum-dead-containers-per-container: 1
docker-address: unix:///var/run/docker.sock
runtime-type: docker
version: 2.0.0
metamanager:
context-send-group: controller
context-send-module: controller
edgesite: true
然后就在cmd目录下直接运行生成的cmd二进制文件了(记得要使用sudo,因为需要创建pods目录)。
1 | ~ $ sudo ./cmd |
原理
前面有讲到,从kubeedge的云边模式,切换到纯边缘部署,代码方面是否可以复用?答案是肯定的,这块kubeedge设计的非常好。要理解这块的原理,需要理解beehive的消息转发。
模块与消息
| 模块 | module name | group name |
|---|---|---|
| deviceTwin | twin | twin |
| edged | edged | edged |
| cloudHub | cloudhub | cloudhub |
| edgeHub | websocket | hub |
| eventbus | eventbus | bus |
| servicebus | servicebus | bus |
| metaManager | metaManager | meta |
| edgeController | controller | controller |
| deviceController | devicecontroller | controller |
模块之间通信的每一个消息都有如下关键组成:
- 消息头信息
- 消息ID
- 消息父ID(请求的返回消息也有同样的该ID)
- 时间戳(消息创建时间)
- 同步消息标识
- 消息路由信息
- 消息来源模块
- 消息目的广播组
- 操作
- 操作资源名称
在之前的架构中,metaManager的消息发送到controller需要经过edgeHub再到cloudHub,然后才能够送到controller。而当前在edgesite中直接取消掉了edgeHub和cloudHub,也就意味着,controller现在是直接将消息送到metaManager。
我们在来看一段controller读取配置文件时候的代码:
1 | const( |
云边模式的情况下使用默认配置,也就是controller发送消息以及发送响应都是往cloudHub发送,而接收都是订阅模块名为controller的消息。在edgesite模式下,配置文件有所变化,我截取edgeSite.yaml的关键部分:
1 | controller: |
至此,我们当值了解了edgesite的大概架构设计,适用场景,以及其代码的巧妙设计。当然,kubeedge还有更多目标,比如对serverless以及serviceMesh的支持等,待后续再慢慢分解。