Redis是一个非常小而美的缓存中间件,官方早期没有集群方案的时候,社区采用哨兵的方式来做集群。官方在3.0版本后开始支持集群方案,但是依然需要至少6台节点,那处于对各种中间件研究的兴趣,我们就来聊聊Redis Cluster希望解决的问题,以及其实现原理。
梗概
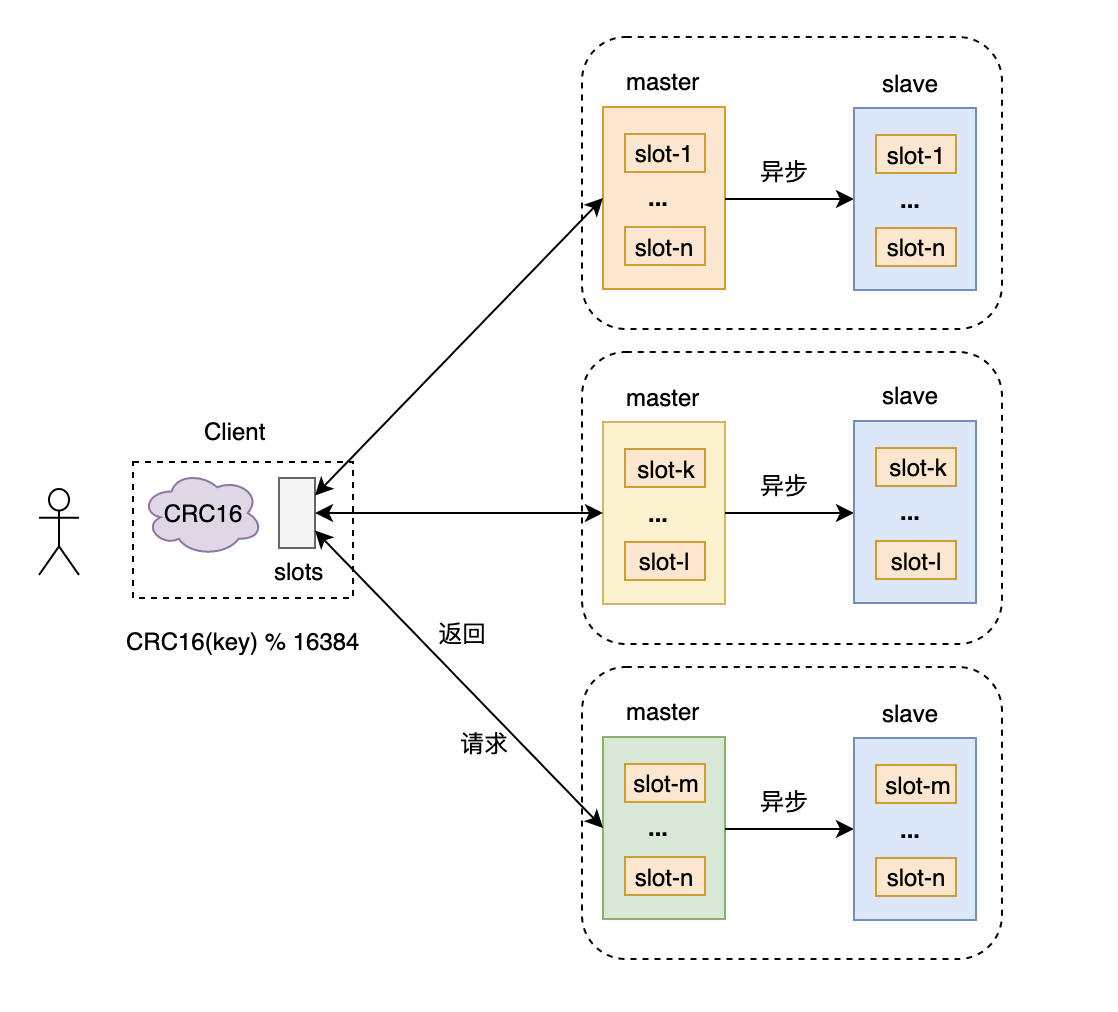
Redis集群的方案解决的终极问题无非三个,大致总结如下:
- 提高整体的可用性
- 横向看,每个集群的master节点都对应有slaves,master挂掉后,新master会从slaves中选举出来;
- 纵向看,每个集群可以手动扩容和缩容,添加减少master节点的数量;
- 支持更大规模的容量(key)
- 采用分片的思想,两层抽象;key被分布到固定数量的slots中,集群masters各服务一部分slots,横向扩容master节点,可以支持更大容量的key;
- 提高整体的吞吐量和性能
- 分片后的,客户端直接计算出key对应slot所在的master节点,直接访问目标master,实现了分布式,从而提高集群整体吞吐量;
集群原理
通过对于问题和解决方式的简单描述,相信大家已经迫不及待的想要知道整个集群的实现原理了。这一章节,就分别来介绍各自的实现。
数据分片
寻址方式
需要注意的是,redis cluster并没有使用一致性哈希来计算key对应的节点,而是通过记录一张映射表 hash slots的方式。由于分层两层结构,从key到slotId这一步还是使用了哈希算法的。
哈希算法(或手动指定)
为了提高客户端快速找到key所在的slot,这里采用了哈希的方式,计算公式是:slotId = crc16(key) % 16384。当然,系统也提供了通过手动的方式来为每一个key指定一个固定的slotId,通过该方式指定的key,在读取的时候也需要指定之前指定的slotId, 否则客户端会默认通过CRC16去计算slotId,导致找不到数据。具体如下:
1
2
3
4
5> set mykey1:{100} 1
> set mykey2 2
(error) MOVED 14119 192.168.99.172:7005
> get mykey2:{100}
"2"hash slots
通过上一步计算得到的slotId快速定位到节点,这里是通过记录一张映射表(slotId->nodeId)的方式来实现的。节点之间通过gossip协议来广播这个关系,可以迅速收敛。如果客户端将不属于该node的一个slot请求发送到该node上,redis会通过查表,快速找到该slot请求本应该去的node,然后向client返回MOVED消息。
客户端实现
单节点redis和redis集群的客户端的实现方式不一样,redis集群客户端的大致处理流程如下:
初始化和正常访问
- 客户端初始化,随机选择一个node通信,获取hashslot->node映射表和nodes信息;
- 向cluster中所有node建立连接,并为每个node创建一个连接池;
- 发送请求的时候,先在本地计算key的hashslot,再在本地映射表找到对应node;
- 若目标node正好持有那个hashslot,那么正常处理.
Slot正在迁移
- 若客户端请求过来是,目标node正在迁移slot,就会返回ASK重定向给客户端(包含了重定向目标node);
- 客户端基于节点信息,向重定向node请求key;但是由于slot正在迁移,
客户端不更新新本地的hashslot->node映射表; - 正在接受迁移的node接收到请求,查询key信息,并返回结果.
Slot已迁移
- 若经过reshard或者slot迁移,hashslot已经不在目标node,就会返回MOVED;
- 客户端收到node返回MOVED,就
更新本地的hashslot->node映射表; - 客户端基于moved node信息请求key。
分片局限性
由于集群采用了将slot分片的方式,因此一些单机版的功能无法适用在集群中。下面是典型的场景:
- key的批量操作支持有限;
- 事务操作支持有限;
- 大的键值对象,如list,hash不能映射到不同节点,只能基于key来映射;
- 只能支持一个db;
- slave的复制只允许有一层;
高可用性
高可用性是集群要达到的一大目标,接下来分别从集群的副本、容错、扩展性几个方面来做介绍。
副本与容错
在Redis集群方案中,每一个master都有对应的slave,当master节点故障的时候,集群能够从备选的slave中选举出新的master节点,从而继续对master上的slots提供对外的服务能力。
节点故障下线
- 通过从Gossip消息中获取到由其他节点判断到的,主观下线的节点列表(需要判断来源是否为主节点,如果一个节点认为某个节点主观下线了,那么会在Gossip ping消息中,ping给其他节点);
- 基于该信息,更新本地的clusterNodes下线列表;
- 基于本地的下线列表,尝试对目标节点进行客观下线;(如果超过半数的节点都认为其主观下线了,就会变成客观下线)
- 向其他节点通告目标节点客观下线消息;(通知其他节点故障节点立即下线,通知slave节点切换为master)。
故障转移
slave节点在感知到master节点挂了之后,该master的所有slave节点会参与选举投票,选举胜出的节点会变为新的master,对外提供服务。
选举流程
- 确认选举资格,没有资格的slave不能参与选举;判断slave节点与主节点失联的时间是否超过指定的时间(每一个从节点都可以设置一个因子来决定其切换的优先级);
- 准备选举时间(延迟触发),每个节点的时间受offset的影响,越接近master的offset越快;
- 投票选举,集群中的主节点对发起投票申请的slave进行投票;
- slave如果获取到绝大多数master的投票,就切换为master;
slave角色切换
- 取消slaveof,并变为master
- 使用
clusterDelSlot取消之前的master上的slot,使用clusterAddSlot将slot委派给自己; - 向集群通告自己变为master
一致性
Redis集群中的epoch有两种:currentEpoch 和 configEpoch。
currentEpoch(整个集群)
currentEpoch代表了整个集群的拓扑版本信息。初始化的时候从0开始,如果节点接收到来自其他节点的包,发送者的currentEpoch大于当前节点的currentEpoch,当前节点就更新 currentEpoch为发送者的currentEpoch。当前currentEpoch只用于slave的故障转移流程。- slave发现其master下线,就会试图发起故障转移流程。首先增加currentEpoch的值,然后向所有节点发起拉票请求。
- 其他节点收到包后,发现发送者的currentEpoch比自己的大,就会更新自己的currentEpoch,并投票。
configEpoch(单个分片内 master+slaves)
configEpoch代表了单个节点配置(所负责的slots)的版本信息。master对外通告其所负责的slots列表,会对应一个configEpoch,所有slave的configEpoch与之一致。一个节点如果收到两个master同时宣称冲突的slot映射消息,就会分别判断两个消息中的configEpoch,并相信更大configEpoch消息中的映射关系。- slave发起选举,成功当选后,会试图替代其已经下线的旧master
- slave增加它自己的configEpoch,使其成为当前所有集群节点的configEpoch中的最大值
- slave向所有节点发送广播包,强制其他节点更新相关slots的负责节点为自己
扩展性
即修改master节点的数量,一般是因为机器数量不够(缩容),或者是希望基于实际业务情况做对外吞吐量的响应调整。需要使用命令:
CLUSTER SETSLOT <slot> (importing|migrating|stable|node <node-id>)
其目的是将slot从一个节点拷贝到另一个节点,具体命令如下:
- 在目标节点执行:
cluster setslot {slot} importing {sourceNodeId} - 在源节点执行:
cluster setslot {slot} migrating {targetNodeId}
常见问题
- 穿透
缓存空值、使用布隆过滤器; - 无底洞问题
分布式缓存中,更多的机器并不一定代表更高的性能; - 雪崩问题
缓存层高可用、客户端降级; - 节点迁移
如果节点没有importing flag, 它会直接设置槽位, 但不会增加自己的node epoch。这样当他告诉别的节点对这个槽位的所有权时, 其他节点并不认可。所以实在要在迁移slot以外的地方用这个命令, 必须要给它发一次cluster bumpepoch。
创建与运维
集群的创建和维护,包含集群握手、slave节点添加、节点slot迁移等操作,具体对应下面三种场景:
集群建立
- 集群节点之间,通过使用服务端口+10000的端口,基于Gossip协议通信握手;
握手执行命令:cluster meet {ip} {port}
可以通过命令:cluster nodes或者cluster info查看 - 分配slot到新加的节点
在目标节点上执行命令:cluster addslots {0..12345}
- 集群节点之间,通过使用服务端口+10000的端口,基于Gossip协议通信握手;
集群副本
- 设置从节点
在slave节点上执行:cluster replicate {master-nodeid}, 指定其属于哪一个master节点的slave
- 设置从节点
集群扩容
- 先通过cluster meet将node加入集群
- 在新加入的(迁移目标)节点执行:
cluster setslot {slot} importing {sourceNodeId} - 在原有的源节点执行:
cluster setslot {slot} migrating {targetNodeId} - 在源节点循环执行:
cluster getkeysinslot {slot} {count}, count为slot的key数量 - 向其他节点执行:
cluster setslot {slot} node {targetNodeId},更新节点的slot映射列表
调试Key
debug object <key>监控面板
1
docker run --name redis-stat -p 8080:63790 -d insready/redis-stat --server {ip-1:port} {ip-2:port} {ip-3:port}
配置信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245[root@vm ~]# redis-cli
127.0.0.1:6379> info
# Server
redis_version:3.2.12
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:7897e7d0e13773f
redis_mode:standalone
os:Linux 3.10.0-693.2.2.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.8.5
process_id:2048
run_id:908bef9f0253572db49ea248a172b4842d81ed35
tcp_port:6379
uptime_in_seconds:2781
uptime_in_days:0
hz:10
lru_clock:6028016
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
# Clients
connected_clients:3
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
# Memory
used_memory:2911368
used_memory_human:2.78M
used_memory_rss:5410816
used_memory_rss_human:5.16M
used_memory_peak:61110496
used_memory_peak_human:58.28M
total_system_memory:1928695808
total_system_memory_human:1.80G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.86
mem_allocator:jemalloc-3.6.0
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1566308627
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
# Stats
total_connections_received:18370
total_commands_processed:3600032
instantaneous_ops_per_sec:0
total_net_input_bytes:192800920
total_net_output_bytes:2634507410
instantaneous_input_kbps:0.01
instantaneous_output_kbps:6.06
rejected_connections:0
sync_full:2
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
evicted_keys:0
keyspace_hits:1000004
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:300
migrate_cached_sockets:0
# Replication
role:master
connected_slaves:0
master_repl_offset:131203668
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:130155093
repl_backlog_histlen:1048576
# CPU
used_cpu_sys:24.04
used_cpu_user:31.68
used_cpu_sys_children:0.01
used_cpu_user_children:0.01
# Cluster
cluster_enabled:0
# Keyspace
db0:keys=6,expires=0,avg_ttl=0
127.0.0.1:6379> config get *
1) "dbfilename"
2) "dump.rdb"
3) "requirepass"
4) ""
5) "masterauth"
6) ""
7) "unixsocket"
8) ""
9) "logfile"
10) "/var/log/redis/redis.log"
11) "pidfile"
12) "/var/run/redis_6379.pid"
13) "slave-announce-ip"
14) ""
15) "maxmemory"
16) "0"
17) "maxmemory-samples"
18) "5"
19) "timeout"
20) "0"
21) "auto-aof-rewrite-percentage"
22) "100"
23) "auto-aof-rewrite-min-size"
24) "67108864"
25) "hash-max-ziplist-entries"
26) "512"
27) "hash-max-ziplist-value"
28) "64"
29) "list-max-ziplist-size"
30) "-2"
31) "list-compress-depth"
32) "0"
33) "set-max-intset-entries"
34) "512"
35) "zset-max-ziplist-entries"
36) "128"
37) "zset-max-ziplist-value"
38) "64"
39) "hll-sparse-max-bytes"
40) "3000"
41) "lua-time-limit"
42) "5000"
43) "slowlog-log-slower-than"
44) "20000"
45) "latency-monitor-threshold"
46) "0"
47) "slowlog-max-len"
48) "1000"
49) "port"
50) "6379"
51) "tcp-backlog"
52) "511"
53) "databases"
54) "16"
55) "repl-ping-slave-period"
56) "10"
57) "repl-timeout"
58) "60"
59) "repl-backlog-size"
60) "1048576"
61) "repl-backlog-ttl"
62) "3600"
63) "maxclients"
64) "10000"
65) "watchdog-period"
66) "0"
67) "slave-priority"
68) "100"
69) "slave-announce-port"
70) "0"
71) "min-slaves-to-write"
72) "0"
73) "min-slaves-max-lag"
74) "10"
75) "hz"
76) "10"
77) "cluster-node-timeout"
78) "15000"
79) "cluster-migration-barrier"
80) "1"
81) "cluster-slave-validity-factor"
82) "10"
83) "repl-diskless-sync-delay"
84) "5"
85) "tcp-keepalive"
86) "300"
87) "cluster-require-full-coverage"
88) "yes"
89) "no-appendfsync-on-rewrite"
90) "no"
91) "slave-serve-stale-data"
92) "yes"
93) "slave-read-only"
94) "yes"
95) "stop-writes-on-bgsave-error"
96) "yes"
97) "daemonize"
98) "no"
99) "rdbcompression"
100) "yes"
101) "rdbchecksum"
102) "yes"
103) "activerehashing"
104) "yes"
105) "protected-mode"
106) "yes"
107) "repl-disable-tcp-nodelay"
108) "no"
109) "repl-diskless-sync"
110) "no"
111) "aof-rewrite-incremental-fsync"
112) "yes"
113) "aof-load-truncated"
114) "yes"
115) "maxmemory-policy"
116) "noeviction"
117) "loglevel"
118) "notice"
119) "supervised"
120) "systemd"
121) "appendfsync"
122) "everysec"
123) "syslog-facility"
124) "local0"
125) "appendonly"
126) "no"
127) "dir"
128) "/var/lib/redis"
129) "save"
130) "900 1 300 10 60 10000"
131) "client-output-buffer-limit"
132) "normal 0 0 0 slave 268435456 67108864 60 pubsub 33554432 8388608 60"
133) "unixsocketperm"
134) "0"
135) "slaveof"
136) ""
137) "notify-keyspace-events"
138) ""
139) "bind"
140) "127.0.0.1"