MySQL的一些集群方案和数据库中间件都在视图解决当表条目变大时,查询性能下降的问题。TiDB的设计原生适用于大规模数据量的存储和查询,重点学习了关于其计算、存储和调度的三篇文档,整理如下。
架构
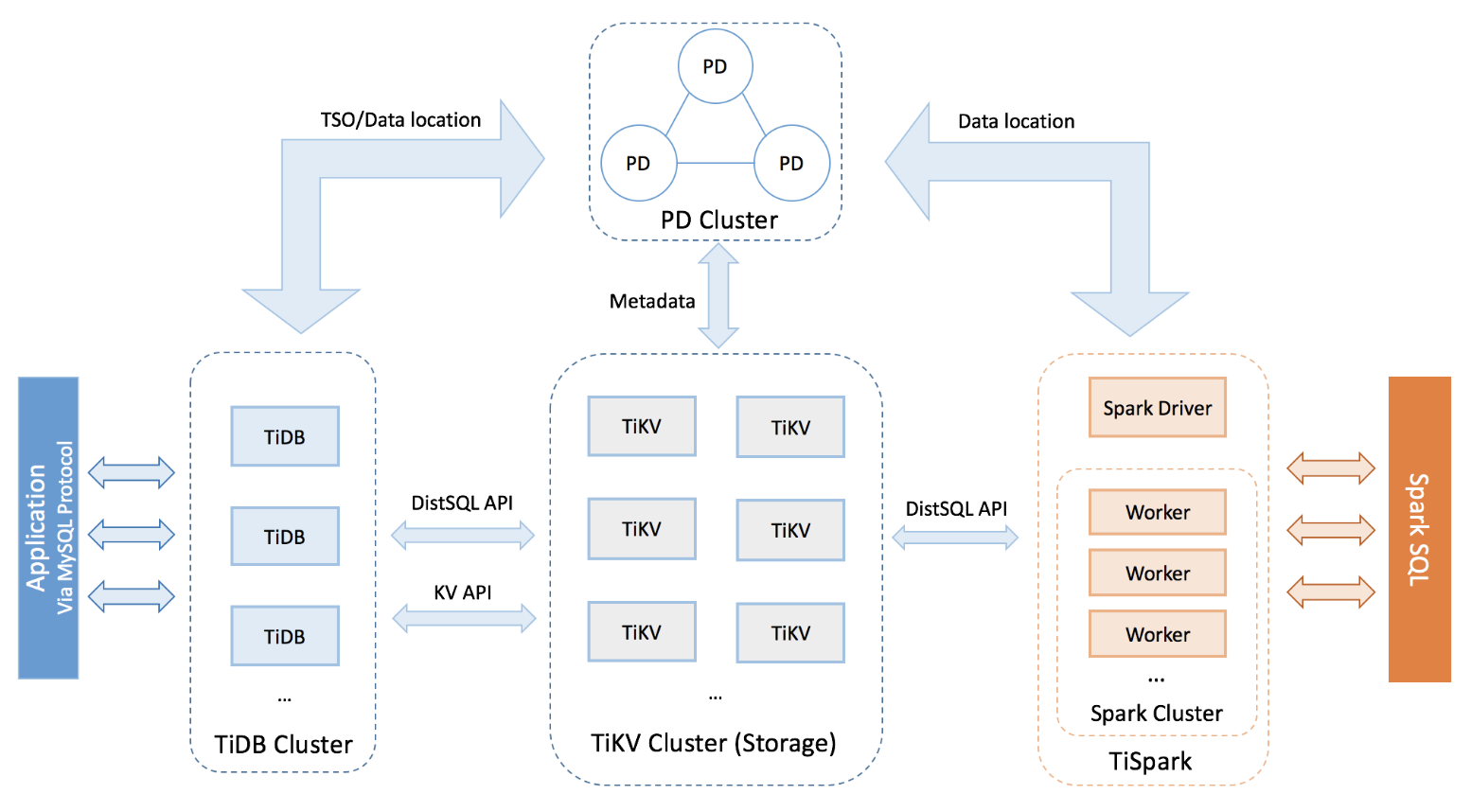
上图展示了TiDB的整体架构设计,重点来看TiDB、PD和TiKV的功能:
TiDB
- 负责接收SQL请求、语法检查
- 做SQL到逻辑查询逻辑的转换
- 基于PD信息将逻辑查询转化为物理查询计划
- 从TiKV获取数据后整合并返回;
PD(Placement Driver)
- 保存SQL逻辑表数据在物理TiKV中分布的映射关系
- 对TiKV集群做调度和负载均衡
- 分配全局事务ID
TiKV
- KV存储引擎
计算(TiDB)
整层架构如下图所示:
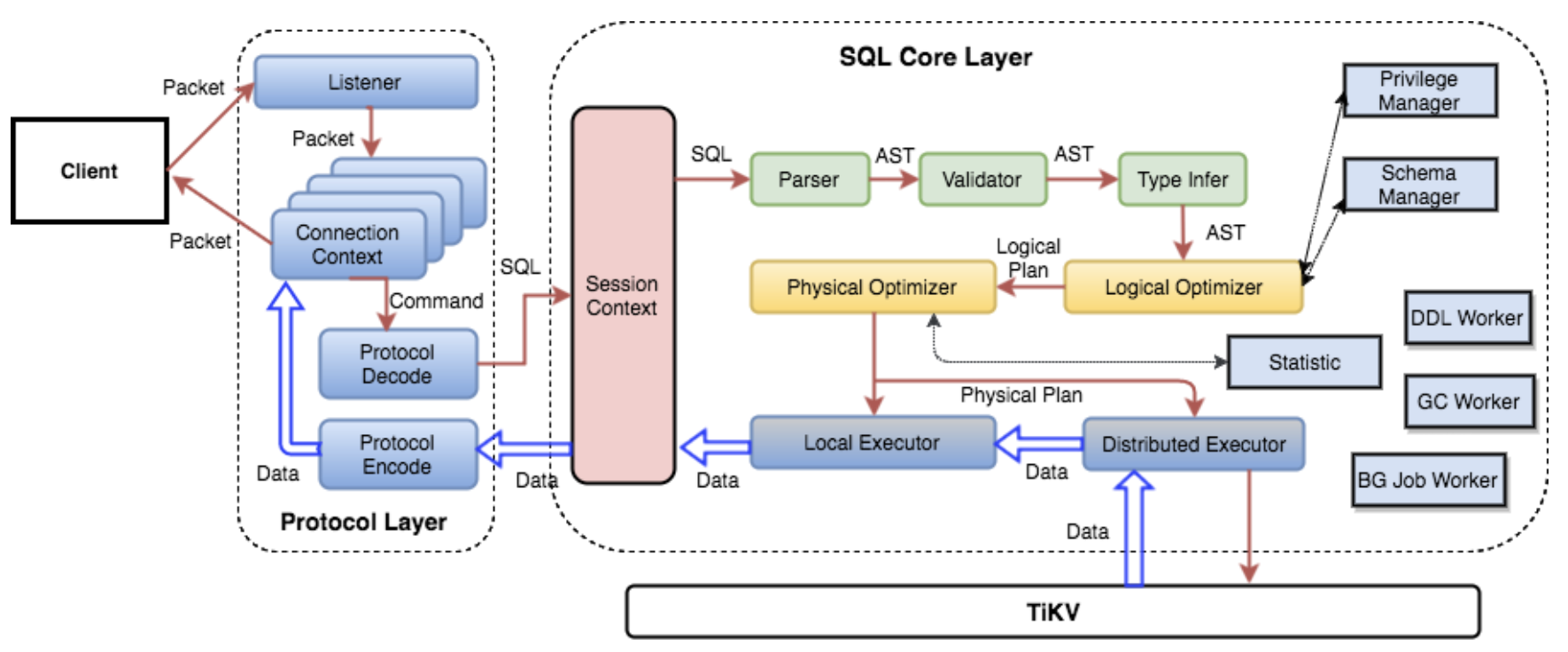
转换规则
TiDB最终是将数据以KV的形势存储到分布式的TIKV上,因此TiDB的重要作用就是做SQL表到KV存储的转换。
对于一个表来讲,需要存储的数据包括:
- 表的元信息
- 表中的条目
- 索引数据
元信息
每个 Database/Table 都被分配了一个唯一的 ID,这个 ID 作为唯一标识,并且在编码为 Key-Value 时,这个 ID 都会编码到 Key 中,再加上 m_ 前缀。这样可以构造出一个 Key,Value 中存储的是序列化后的元信息。
表条目
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID),行记录转换方式为:
1 | Key: tablePrefix{tableID}_recordPrefixSep{rowID} |
实例: SQL表格式
1 | 1, "TiDB", "SQL Layer", 10 |
Row转换后
1 | t10_r1 --> ["TiDB", "SQL Layer", 10] |
索引数据
Unique Index
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue |
非 Unique Index
1 | Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID |
实例
1 | t10_i1_10_1 --> null |
操作与查询过程
对数据的操作包括:
- 对于 Insert 语句,需要将 Row 写入 KV,并且建立好索引数据。
- 对于 Update 语句,需要将 Row 更新的同时,更新索引数据(如果有必要)。
- 对于 Delete 语句,需要在删除 Row 的同时,将索引也删除。
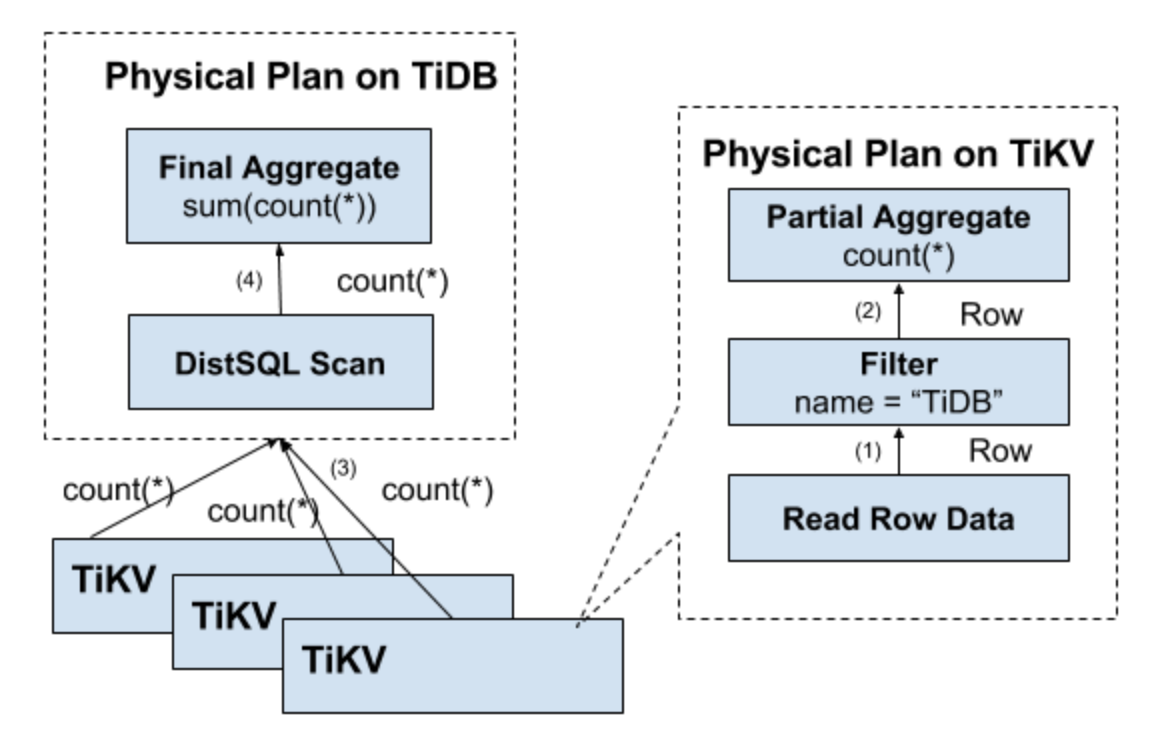
执行查询语句Select count(*) from user where name="TiDB”;流程:
- 构造出 Key Range:一个表中所有的 RowID 都在 [0, MaxInt64) 这个范围内,那么我们用 0 和 MaxInt64 根据 Row 的 Key 编码规则,就能构造出一个 [StartKey, EndKey) 的左闭右开区间
- 扫描 Key Range:根据上面构造出的 Key Range,读取 TiKV 中的数据
- 过滤数据:对于读到的每一行数据,计算 name=”TiDB” 这个表达式,如果为真,则向上返回这一行,否则丢弃这一行数据
- 计算 Count:对符合要求的每一行,累计到 Count 值上面 这个方案肯定是可以 Work 的,但是并不能 Work 的很好,原因是显而易见的:
为了减少网络开销,会尽量将一些计算下沉到TiKV, 比如将上面的扫描KeyRange、过滤数据和计算Count都放到TiKV, 然后基于各个分布式TiKV计算之后,将结果再上报到TIDB做汇总。
存储(TiKV)
TiKV的存储需要解决一下问题:
- 如何高效存储和访问;
- 数据冗余与一致性问题;
- 当数据量太大的时候,如何解决前面两个问题;
如何高效存储和访问
- 这是一个巨大的 Map,也就是存储的是 Key-Value pair(底层是采用RocksDB一个单机的 Key-Value Map存储)
- 这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是我们可以 Seek 到某一个 Key 的位置,然后不断的调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value
MVCC
TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现的。 key的排列变成这样:
1 | Key1-Version3 -> Value |
TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。
数据冗余与一致性问题
- 通过在多台物理节点上保存多个副本来做冗余;
- 使用raft协议来保障数据的一致性;
总结起来就是下图的架构设计,通过单机的 RocksDB,我们可以将数据快速地存储在磁盘上;通过 Raft,我们可以将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。

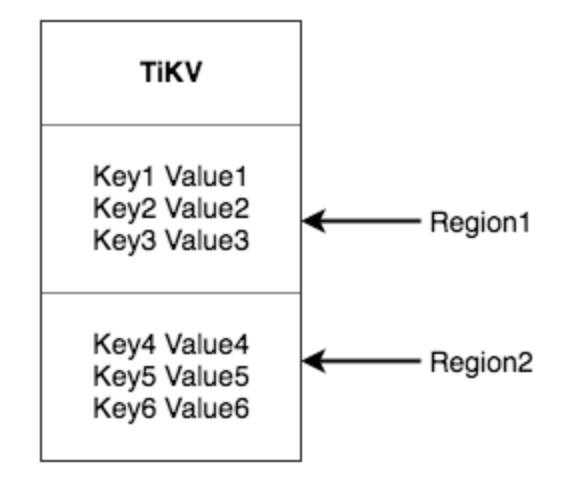
Region
- 将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,每一段叫做一个 Region;
- 尽量保持每个 Region 中保存的数据不超过一定的大小(默认是 64mb);
- 每一个 Region 都可以用 StartKey 到 EndKey 这样一个左闭右开区间来描述。
当数据量大时,如何解决前两个问题
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多;
- 以 Region 为单位做 Raft 的复制和成员管理;
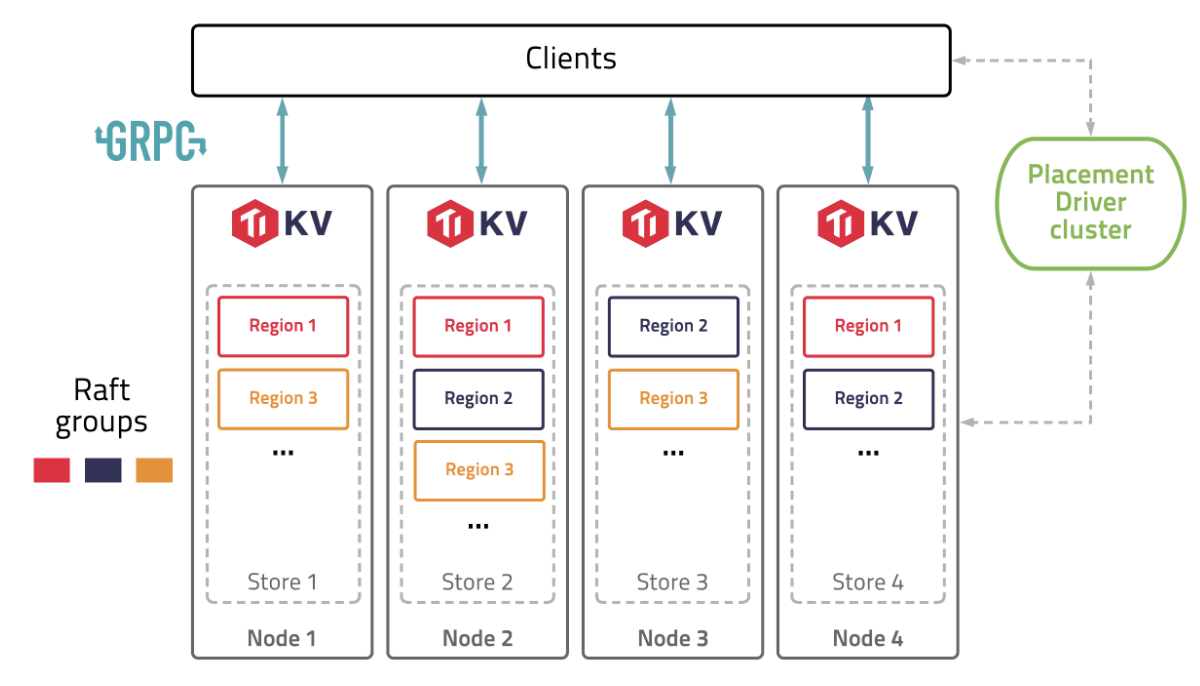
调度(PD)
Pd之间本身通过etcd来实现分布式高可用容错和数据的一致性;
信息收集
- 每个 TiKV 节点会定期向 PD 汇报节点的整体信息
- 每个 Raft Group 的 Leader 会定期向 PD 汇报信息
调度策略
- 一个 Region 的 Replica 数量正确
- 一个 Raft Group 中的多个 Replica 不在同一个位置
- 副本在 Store 之间的分布均匀分配
- Leader 数量在 Store 之间均匀分配
- 访问热点数量在 Store 之间均匀分配
- 各个 Store 的存储空间占用大致相等
- 控制调度速度,避免影响在线服务
- 支持手动下线节点
调度实现
- PD 不断的通过 Store 或者 Leader 的心跳包收集信息,获得整个集群的详细数据
- 根据这些信息以及调度策略生成调度操作序列
- 收到 Region Leader 发来的心跳包时,PD 都会检查是否有对这个 Region 待进行的操作,通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果
binlog
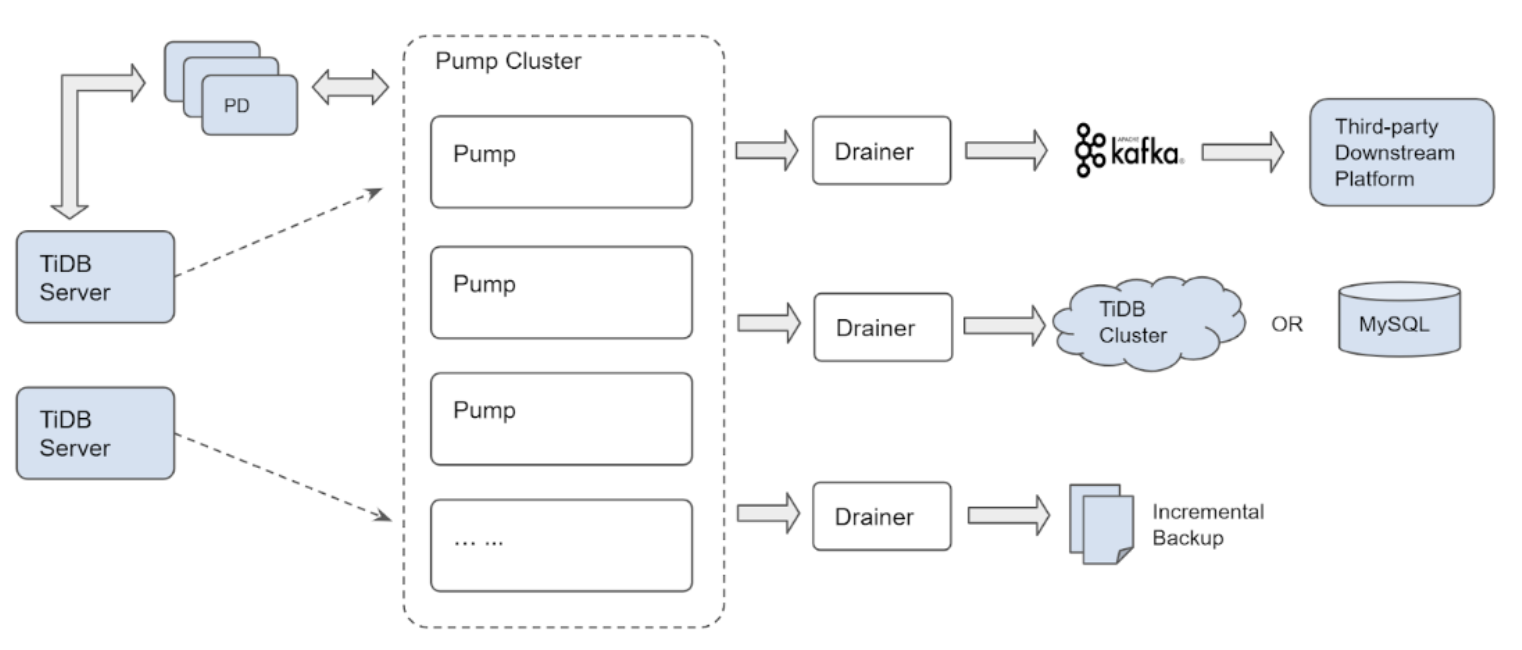
- TiDB 实例连接到各个 Pump 节点并发送 binlog 数据到 Pump 节点。
- Pump 集群连接到 Drainer 节点,Drainer 将接收到的更新数据转换到某个特定下游(例如 Kafka、另一个 TiDB 集群或 MySQL 或 MariaDB Server)指定的正确格式。
数据热点问题
为解决热点问题,TiDB 引入了预切分 Region 的功能,即可以根据指定的参数,预先为某个表切分出多个 Region,并打散到各个 TiKV 上去。
1 | SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num |
BETWEEN lower_value AND upper_value REGIONS region_num 语法是通过指定上、下边界和 Region数量,然后在上、下边界之间均匀切分出 region_num 个 Region。
1 | SPLIT TABLE table_name [INDEX index_name] BY (value_list) [, (value_list)] ... |
BY value_list… 语法将手动指定一系列的点,然后根据这些指定的点切分 Region,适用于数据不均匀分布的场景
均匀切分
由于 row_id 是整数,所以根据指定的 lower_value、upper_value 以及 region_num,可以推算出需要切分的 key。TiDB 先计算 step(step = (upper_value - lower_value)/num),然后在 lower_value 和 upper_value 之间每隔 step 区间切一次,最终切出 num 个 Region。
1 | SPLIT TABLE t BETWEEN (-9223372036854775808) AND (9223372036854775807) REGIONS 16; |
不均匀切分
如果已知数据不是均匀分布的,比如想要 -inf ~ 10000 切一个 Region,10000 ~ 90000 切一个 Region,90000 ~ +inf 切一个 Region,可以通过手动指定点来切分 Region,示例如下:
1 | SPLIT TABLE t BY (10000), (90000); |